
Python in Action: Machine Learning
Learn why Python is the most popular language for this subfield of AI
Hey Grokking Python readers!
Most people interact with machine learning processes every day, though they might not always be aware of it. Machine learning is a subfield of artificial intelligence (AI). It works by running data through algorithms that train software to make decisions, classifications, and predictions on the basis of certain inputs. Any time you encounter an automated system that makes decisions or recommendations in response to a given set of inputs, that system is probably a product of machine learning.
An example you might be familiar with is the recommended content category in your Netflix account.
This content is selected by an algorithm that parses your viewing history to make predictions about what TV shows and movies you’ll find interesting. A similar process occurs when your credit card is locked due to suspicious activity. Just as your viewing history allows Netflix’s algorithm to predict what content you’ll enjoy, your past credit card transactions allow your bank to judge whether a new transaction is in character for your account. Machine learning is therefore a key part of many of the applications we use on a daily basis, making it an essential part of the architecture of our hyper-online world.
Newcomers to the fields of machine learning and data science generally want to know what programming language they should use. There’s no easy answer to this, as different languages have different advantages and drawbacks. A language might lend itself to some machine learning tasks but not others. While there may not be a “best” language for machine learning, there’s definitely one that’s most popular. That language is Python.
In this issue of Grokking Python, we’ll explore the strengths that make Python the most popular language for machine learning. We’ll also take a look at some resources you can use to get started using Python for machine learning projects.
How machine learning works
Machine learning algorithms are generally divided into four categories: supervised, unsupervised, semi-supervised, and reinforcement.
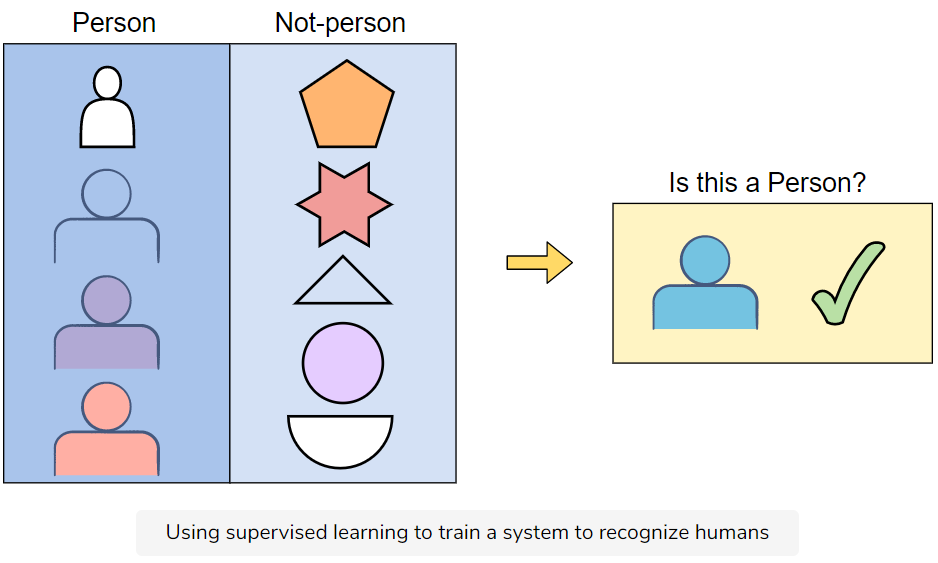
Supervised machine learning uses labeled data sets to train algorithms to perform classifications and predictions accurately.
Unsupervised machine learning involves engaging with unlabeled data sets. It uses algorithms to organize data based on patterns of similarity and difference. So, if supervised machine learning requires a human actor to organize and label the data that will be used to train the algorithm, unsupervised machine learning performs those tasks independently. It’s used to identify relationships, patterns, and so on within bodies of unlabeled data.

Semi-supervised machine learning is a model that incorporates both supervised and unsupervised elements. Think of it as a middle-of-the-road approach that is designed to avoid some of the pitfalls of the former two models. Supervised models tend to yield more accurate results, but this is because of the labor-intensive process of labeling data sets to train the algorithm. Unsupervised models don’t require this labor upfront, and they can be extremely useful in processing large quantities of unclassified data. However, they can also yield less accurate results, such that data scientists still need to analyze the algorithm’s outputs to verify their accuracy. Semi-supervised models are a useful alternative insofar as they act on a mixed collection of data, some of it labeled and some of it unlabeled. The labeled data can train the algorithm to process the unlabeled data more accurately.
Reinforcement machine learning is a little different. It works by performing actions and receiving positive or negative feedback for those actions. Over time, the system learns what actions to perform in order to maximize positive feedback.

What programming language should you use for machine learning?
As noted above, there arguably isn’t a “best” language for machine learning. The language you use will generally depend on the specific task you’re performing. For example, R was designed by statisticians, and it lends itself to mathematical computing. So, if the machine learning task at hand involves statistical analysis and data visualization, you might decide that R is the best language for your purpose.
Python, however, consistently ranks as the most widely-used language for machine learning due to its user-friendly syntax, its portability, and its copious open-access libraries (some of which are designed specifically for machine learning projects).
In short, if you’re pursuing a career in machine learning and data science, you’ll probably find it beneficial to be familiar with multiple languages so that you can choose whichever one best suits the project you’re working on. Given how widespread and user-friendly Python is, it’s probably the best place to start this learning process.
Why Python?
The qualities that make Python the most widely-used language for machine learning and data science are some of the same qualities that make it one of the most popular programming languages, generally.
Python’s syntax is famously easy to learn (at least relative to other programming languages). As a free, open-source language, it’s also easy to access Python and apply it to a range of programming tasks.
Python is also portable, meaning that Python applications can run on multiple operating systems, including Windows and MacOS.
For these reasons and others, it’s simply the case that a lot of people use Python. A large and engaged community has formed around the language over the years, resulting in an abundance of documentation and support for users.
Finally, for the purposes of machine learning, Python’s most important distinguishing feature is that it has numerous expansive libraries. Some of these Python libraries were compiled specifically for use in machine learning and data science. Here are some of the libraries most frequently used for machine learning.
NumPy is an open-source Python library that’s used for complicated mathematical operations. It’s compatible with some of the other libraries listed below such as Pandas, Matplotlib, and Scikit-learn.
SciPy is an open-source library that builds on NumPy with a range of algorithms for scientific computing applications.
Pandas is another open-source library. It provides a range of tools for data analysis and manipulation, and it’s frequently used in conjunction with NumPy, SciPy, and Matplotlib.
Matplotlib is the most popular Python library for data visualization and 2-D plotting.
Seaborn is built on Matplotlib and can be used for plotting statistics and generating accessible graphics.
TensorFlow is an open-source machine learning platform. In addition to providing robust libraries for machine learning in Python, it includes a range of tools and user resources that facilitate highly portable machine learning models.
Scikit-learn is another popular, open-source Python library. Built on NumPy, SciPy, and Matplotlib, it is frequently used for running classification, regression, and clustering algorithms.
Getting started
Now that you know the basics of machine learning in Python, how can you start building on your knowledge and developing some practical skills?
Educative’s introductory course on data science and machine learning could be a good place to start. In addition to providing a more in-depth series of lessons on these topics, the course also provides hands-on coding environments that will allow you to practice machine learning skills. If you already have some experience with data science and machine learning and are preparing for a job interview, consider Educative’s Grokking the Machine Learning Interview course.
Is there a Python use-case you’d like us to cover in a future installment of Python in Action? Let us know in the comments or by replying to this email.
As always, happy learning!